1 Introduction
I recently came across a problem known as time series downsampling. Having many observations at a certain time granularity level (second, minute, hour, etc.) the idea is to go one (or more) level up. That way, from a set of observations within a time frame, we want to select one observation and keep it.
But how do we know which observation to keep? Should we keep the first observation in the set? Or the last one? Or maybe the average of all the observations? In order to do so, we will need an aggregate function.
2 Refreshers
Let’s first recap some concepts:
In mathematics, a time series is a series of data points indexed (or listed or graphed) in time order. Most commonly, a time series is a sequence taken at successive equally spaced points in time.
Downsampling referes to the process of changing the granularity of our data to a coarser grain, for example, changing from seconds to minutes.
An aggregate function performs a calculation on a set of values, and returns a single value. Examples:
AVG(),MAX(),MIN(),COUNT()

Using the definitions above, we want to downsample our time series using an aggregate function.
3 Example context
Suppose we collect temperature data on a machine up to the second granularity by means of a sensor. To add an extra layer of complexity, these measurements are taken at random intervals: some times we collect 25 observations per minute, others 42 observations, others 60, and so on.
But for our business case keeping only the most recent observation is fine. Restating our problem: from the set of observations the sensor collects per minute, we want to keep only 1 (the most recent). Example:
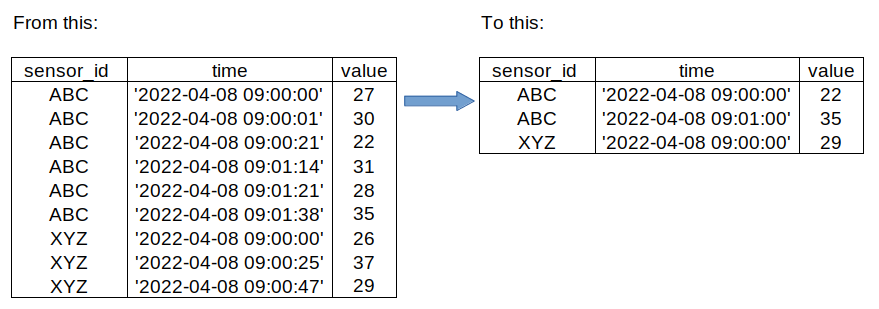
4 Data base set up
In order to follow along with the example, we are going to spin up a Postgres SQL database within a docker container, load some data and downsample it. Please refer to the README in the repo here: https://github.com/canovasjm/sql-times
5 CREATE table and INSERT data
Let’s create a table an insert some data.
-- Example 1: data granularity is in seconds, we want
-- want to roll up to the minute
-- drop the table if exists
DROP TABLE IF EXISTS atable;
-- create the table
CREATE TABLE atable (
sensor_id text,
time timestamp without time zone,
value smallint
);-- insert some sample data
INSERT INTO atable (sensor_id, time, value)
VALUES ('ABC', '2022-04-08 09:00:00', 27);
INSERT INTO atable (sensor_id, time, value)
VALUES ('ABC', '2022-04-08 09:00:01', 30);
INSERT INTO atable (sensor_id, time, value)
VALUES ('ABC', '2022-04-08 09:00:21', 22);
INSERT INTO atable (sensor_id, time, value)
VALUES ('ABC', '2022-04-08 09:01:14', 31);
INSERT INTO atable (sensor_id, time, value)
VALUES ('ABC', '2022-04-08 09:01:21', 28);
INSERT INTO atable (sensor_id, time, value)
VALUES ('ABC', '2022-04-08 09:01:38', 35);
INSERT INTO atable (sensor_id, time, value)
VALUES ('ABC', '2022-04-08 09:02:07', 33);
INSERT INTO atable (sensor_id, time, value)
VALUES ('ABC', '2022-04-08 09:02:11', 19);
INSERT INTO atable (sensor_id, time, value)
VALUES ('ABC', '2022-04-08 09:02:56', 25);
INSERT INTO atable (sensor_id, time, value)
VALUES ('XYZ', '2022-04-08 09:00:00', 26);
INSERT INTO atable (sensor_id, time, value)
VALUES ('XYZ', '2022-04-08 09:00:25', 37);
INSERT INTO atable (sensor_id, time, value)
VALUES ('XYZ', '2022-04-08 09:00:47', 29);-- check what we have in `atable`
SELECT * FROM atable;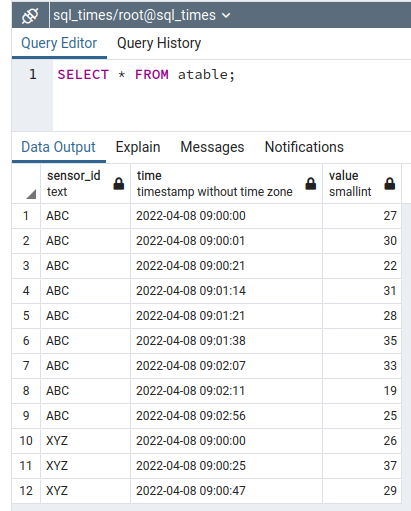
6 date_trunc() to the rescue
The code to downsample is provided by Andriy M in this Stack Overflow question: https://stackoverflow.com/questions/7335627/sampling-sql-timeseries
But this code will not work as is in Postgres, so I made a minor modification using a Postgres specific function: date_trunc().
More details about date_trunc() here: https://www.postgresql.org/docs/current/functions-datetime.html#FUNCTIONS-DATETIME-TRUNC
-- see how date_trunc() works
SELECT
sensor_id,
date_trunc('minute', time) AS truncated_time,
value
FROM atable;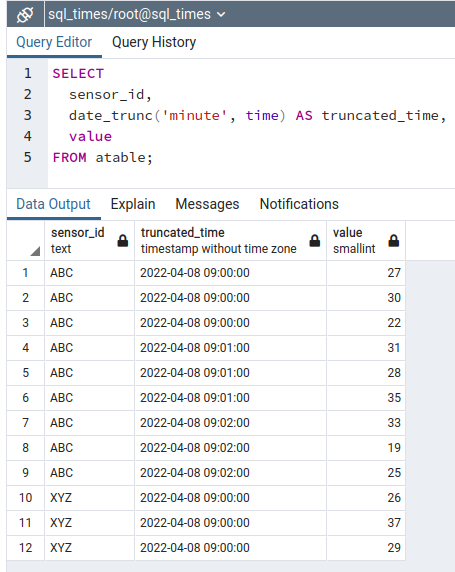
As we see above, date_trunc() is just truncating the seconds of the timestamps.
7 Downsampling
Back to the answer from Andriy M in Stack Overflow, let’s run the code to downsample with our date_trunc() modification:
-- query to get only the most recent
-- data point within a minute
SELECT
t.* /* you might want to be more specific here */
FROM atable t
INNER JOIN (
SELECT
sensor_id,
MAX(time) AS time
FROM atable
GROUP BY sensor_id, date_trunc('minute', time)
) m ON t.time = m.time AND t.sensor_id = m.sensor_id
ORDER BY sensor_id, time; -- ORDER BY is optionalThe code above can be rewritten more elegantly using a CTE, so here we go:
-- query to get only the most recent
-- data point within a minute, with CTE
WITH times_cte AS
(
SELECT
sensor_id,
MAX(time) AS time
FROM atable
GROUP BY sensor_id, date_trunc('minute', time)
)
SELECT
t.* /* you might want to be more specific here */
FROM atable t
INNER JOIN times_cte m
ON t.time = m.time AND t.sensor_id = m.sensor_id
ORDER BY sensor_id, time; -- ORDER BY is optional8 Dissecting our CTE
The query inside the WITH statement, i.e:
SELECT
sensor_id,
MAX(time) AS time
FROM atable
GROUP BY sensor_id, date_trunc('minute', time)Gives the following result:
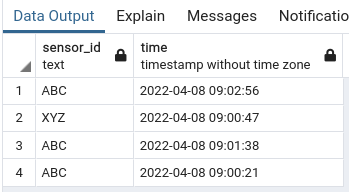
As Andriy M explains in his answer, the next step is to join the obtained list back to the original table to pull the data for the obtained timestamps.
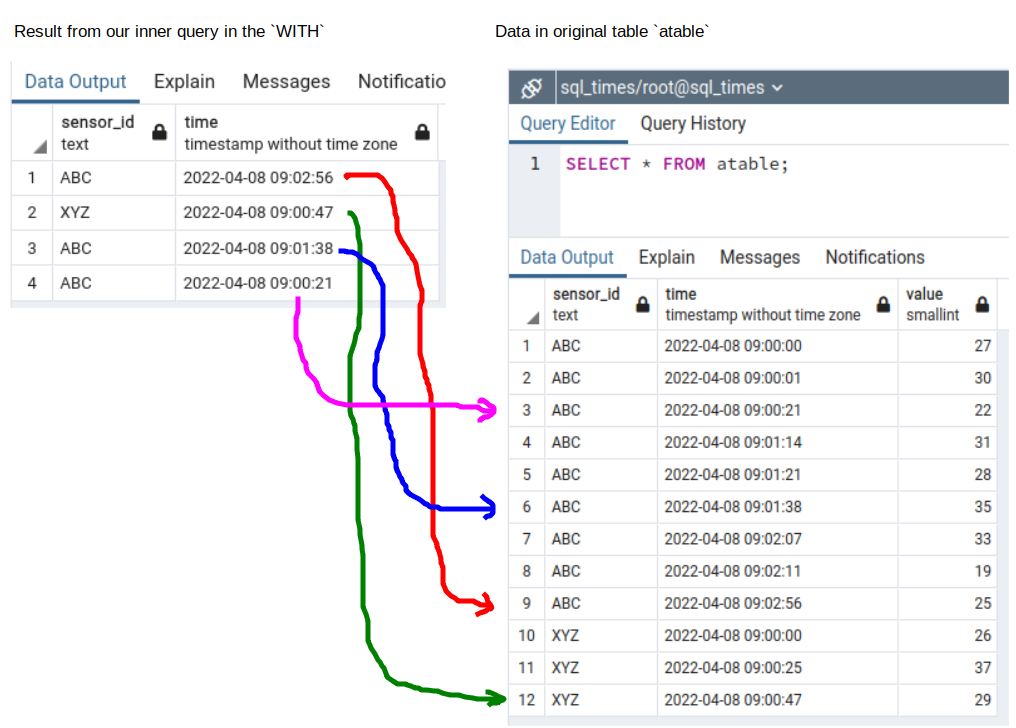
Next, the lines:
INNER JOIN times_cte m
ON t.time = m.time AND t.sensor_id = m.sensor_idwill pull the information from the value column. Running the entire query:
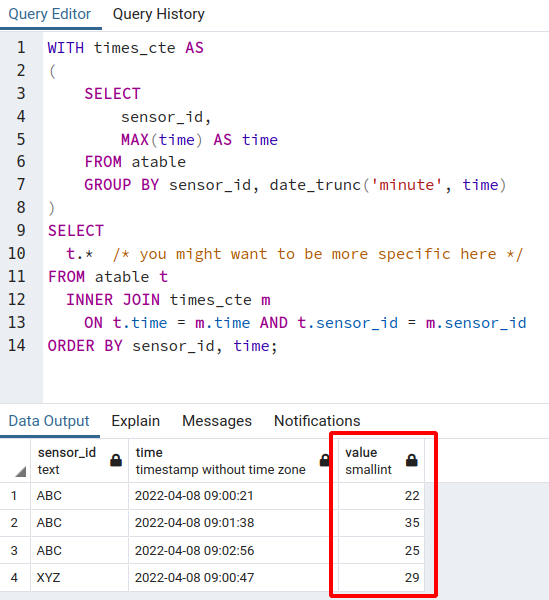
We can see the ‘value’ column now.
9 Conclusion
In this post we covered how to downsample a time series using SQL and a very simple example.
Do you know other ways to downsample time series? Please leave a comment and tell us more!
Did you spot an error in the code or a typo? Feel free to leave a comment, raise in issue or open a PR on the GitHub repo :)
10 References
Downsampling code from Stack Overflow question:
https://stackoverflow.com/questions/7335627/sampling-sql-timeseries
Wikipedia on time series:
https://en.wikipedia.org/wiki/Time_series
Course by Kevin Feasel on Data Camp:
https://campus.datacamp.com/courses/time-series-analysis-in-sql-server/aggregating-time-series-data?ex=8
Microsoft’s docs on aggregate functions:
https://docs.microsoft.com/en-us/sql/t-sql/functions/aggregate-functions-transact-sql?view=sql-server-ver16